This blog explores how to use Argo Rollouts for deploying software updates smoothly. It covers the challenges faced when rolling back updates and introduces header-based routing to manage traffic during deployments.
Scenario
Following the deployment of one of our client-critical services, we saw an application bug after we rolled out a service to 100% of users, so the only option left for us is to quickly rollback to the older version. But that also took some time, as the rollback process was not fast in the older setup.
Why was the rollback the only option we had?
Our new feature led to an incident, and unfortunately, disabling it wasn’t feasible. Without feature flags in place, executing a full rollback was the sole method available to us for recovery.
Why is the rollback process very slow?
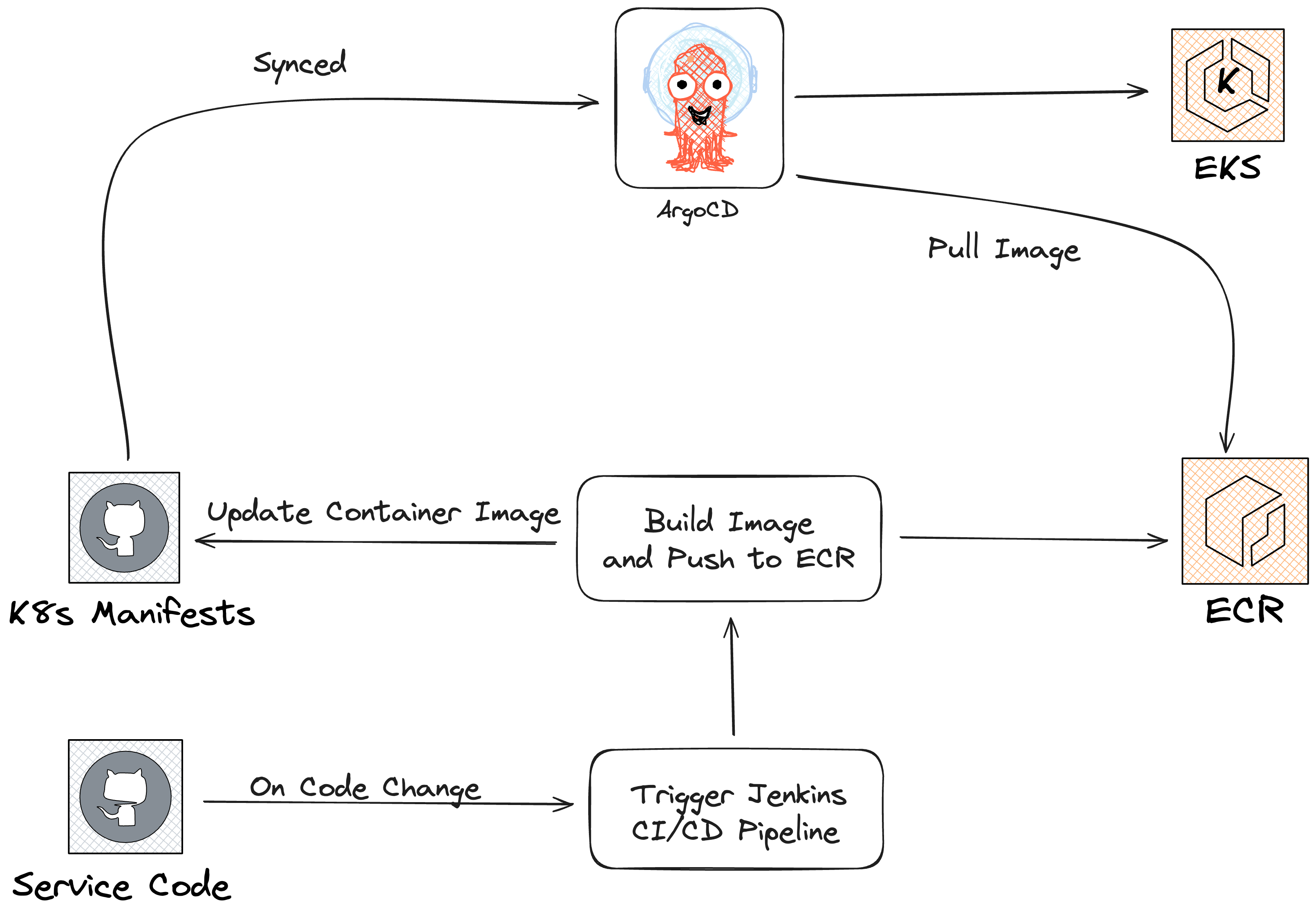
To comprehend this, let’s delve into the current setup of our organizational services. Essentially, all our client services are hosted in Kubernetes (K8s) via AWS EKS. The Kubernetes manifests are managed within our organization, with one such repository residing on GitHub, which is then synchronized with ArgoCD. In terms of deployment strategy, we’ve embraced Argo-Rollout Canary as it empowers us with automated progressive delivery.
Still, you didn’t get the answer to the question, correct?
Hold on! Argo Rollout has the quick feature of rollback from their dashboard, but here is the limitation. Argo Rollout while doing rollback, it doesn’t update the k8s manifest stored in the Github repo, which is synced with ArgoCD. As a result, ArgoCD goes into OutOfSync and again updates the container image from the older version to the current version.
So then, how did we do the rollback?
It was the same as the new deployment, just with older code. We reverted the PR of the feature being added again and ran the deployment pipeline, which was setup in Jenkins, which then went through testing, building an image, pushing it to ECR, and then deploying by updating the container image, which then updated the K8S manifests stored in the Github repo, which were then synced by the ArgoCD. Hence, the rollback procedure was just a new deployment, although with the previous codebase.
What were the action items?
We acknowledged that responsibility for the incident wasn’t solely on the Dev & QA teams for missing the bug during testing and not having the feature flag. The SRE team was also called out for the slow or lack of rollback process. Additionally, there was a demand for enhancing the deployment process to verify critical features, especially those likely to behave differently in production, either before any traffic hits or on a minimal percentage of real traffic, perhaps around 1%.
Proposed Solutions
Improving Rollback Process:
We updated our Jenkins pipeline to include a new step called “Promotion.” This addition allows the pipeline to pause for a maximum of 30 minutes, awaiting a decision on the success of the deployment. Depending on this decision, an automated rollback operation is initiated, reverting to the previous container image by updating the Kubernetes manifest stored in our GitHub repository, subsequently synced by ArgoCD.
Exploring Routing Techniques:
In addressing the need for enhanced routing during deployment, we investigated options and found that Argo Rollout supports header-based routing for the alb controller, although in its alpha stage. We’re considering testing this feature to see if it meets our requirements.
Argo Rollout header-based routing
How does the Argo Rollout work?
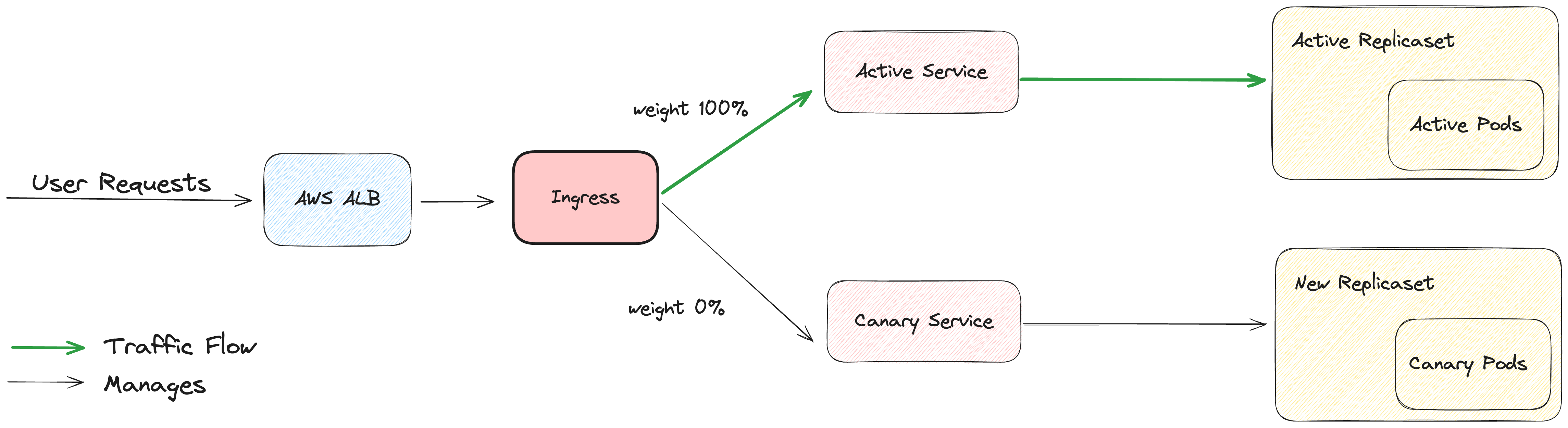
Argo Rollout manages two services: the active service and the canary service, if utilizing the canary strategy. These services are represented as target groups on the AWS ALB console. The active service typically starts with a 100% weight, while the canary service begins with a 0% weight.
During each deployment, the weight distribution between the active and canary services changes. Think of them as different phases of deployment, similar to a “blue” or “green” deployment approach. However, the canary deployment offers a progressive strategy, allowing for gradual traffic shifting through defined steps outlined in the rollout manifest.
These steps may include various analysis checks, pauses, or adjustments in traffic distribution, ensuring a smooth deployment process while minimizing disruptions.
How does the Argo Rollout deployment flow work?
Initial State:
- The active service is initially responsible for serving all incoming traffic.
Start of New Deployment:
- When a new deployment begins, traffic gradually starts shifting to another service known as the Canary service.
- The Canary service directs traffic to the pods of the new deployment.
Progressive Traffic Shifting:
- Over time, as the deployment progresses, more and more traffic is directed to the Canary service.
- This shift continues until the entirety of the traffic is directed to the Canary service.
Completion of Deployment:
- Once all traffic has been shifted to the Canary service, it becomes the active service.
- At this point, the previous active service becomes the Canary service, ready for future deployments.
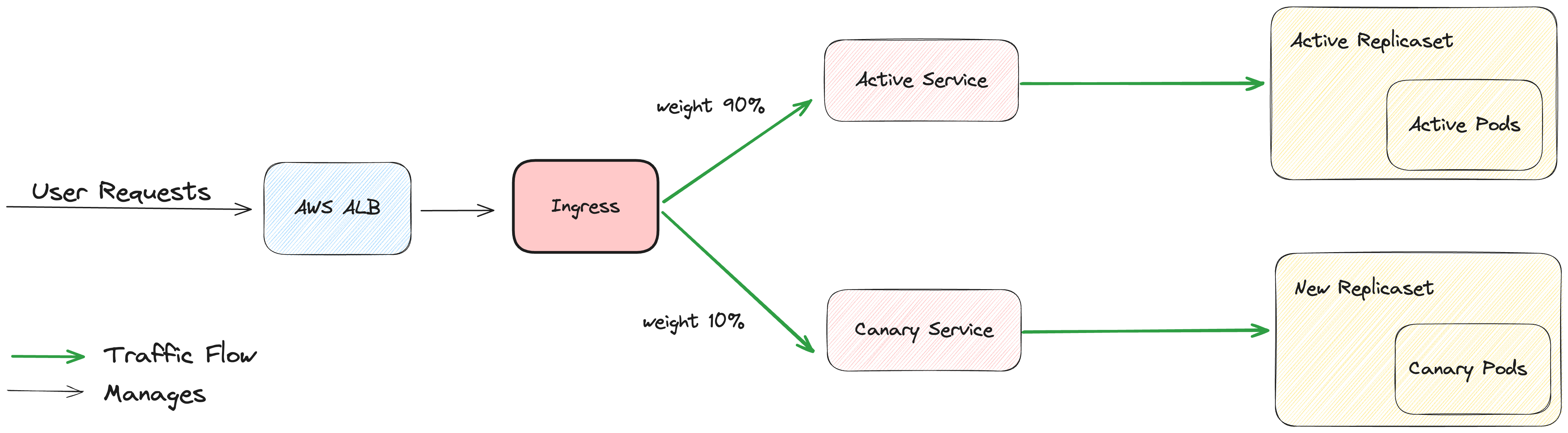
How does Argo Rollout header-based routing work then?
Routing Traffic with Specific Headers
- With header-based routing, all traffic containing a specific header key and value is directed to the Canary service.
- Previously, this Canary service wasn’t serving traffic, but now it ensures that requests during deployment hit the new pods, and responses are received from them.
Managing Canary Steps
- Within the canary steps, we have the option to specify the duration of pauses between stages to validate the deployment.
- This allows for careful monitoring and testing of the new deployment before fully transitioning traffic to it.
On implementing header-based routing, how will things look?
Suppose below are the canary steps if we were using:
steps:
- setCanaryScale:
weight: 10
- setHeaderRoute:
match:
- headerName: version
headerValue:
exact: "2"
name: canary-header-route-new
- pause:
duration: 60s
- setWeight: 1
- pause: {}
- setCanaryScale:
matchTrafficWeight: true
- pause:
duration: 20
- setWeight: 80
- pause:
duration: 20
setCanaryScale: It will tell us how much of a percentage of new pods to scale up.
setHeaderRoute: It will set the key-value pair to header, which will then create a new alb listener that will always point to canary-service.
pause: It will give a finite or indefinite pause to your deployment process so that it will take some time on each percentage of traffic shift to verify the new pods, metrics, and monitoring that we have set up. In case of indefinite pause, we manually need to do promotion (Argo Rollout has this feature to promote).
setWeight: It will tell us how much percentage of traffic is to be shifted to new pods.
matchTrafficWeight: By marking it true, it will tell the Argo Rollout to scale up the pods based on the traffic shift. The default value is true.
Let’s look in detail at how we can visualize this configuration
Step 1: We will scale the 10% of pods in the total replica pods; consider that the total replica pods are 10; then, 1 new pod will be up after the 1st step.
Step 2: It will create a new listener in AWS ALB with the same host and path but an additional header with lower priority, so that requests with a specific header should go to new pods instead of older pods by the existing listener.

Step 3: Deployment will be paused for 60 seconds so that you can perform testing by hitting the same endpoint with the header, whether the requests are going to newer pods or not.
Step 4: Here we will be shifting 1% of production traffic to newer pods, which will come from the existing listener, but now you have some percentage of traffic on newer pods, and hence you can perform more comprehensive testing by using the same technique of header-based testing to hit new pods.

- Step 5: This step will put your deployment into an indefinite pause such that until you perform the Promote manually, deployment will not move. This type of step is really helpful when you need to run some long tests to get the critical features tested.
Similarly, it will perform all the steps, and after the complete deployment, or in the case of abortion, it will delete the additional listener added by the Argo Rollout.
Great! We achieved the solution to our problem, right? Yes, but it is not working!
Why won’t header-based routing work?
So, as I said earlier, also, our K8s manifest files are synced from the Github repo. Due to header-based routing, it will add some additional paths to ingress that will point to specific services (which will serve the traffic in the next deployment). And again, we faced an OutOfSync Error.
Let’s see how the ingress will look after Step 2 (considering the same rollout steps configuration as shown above). If there is ArgoCD, auto-sync is off.
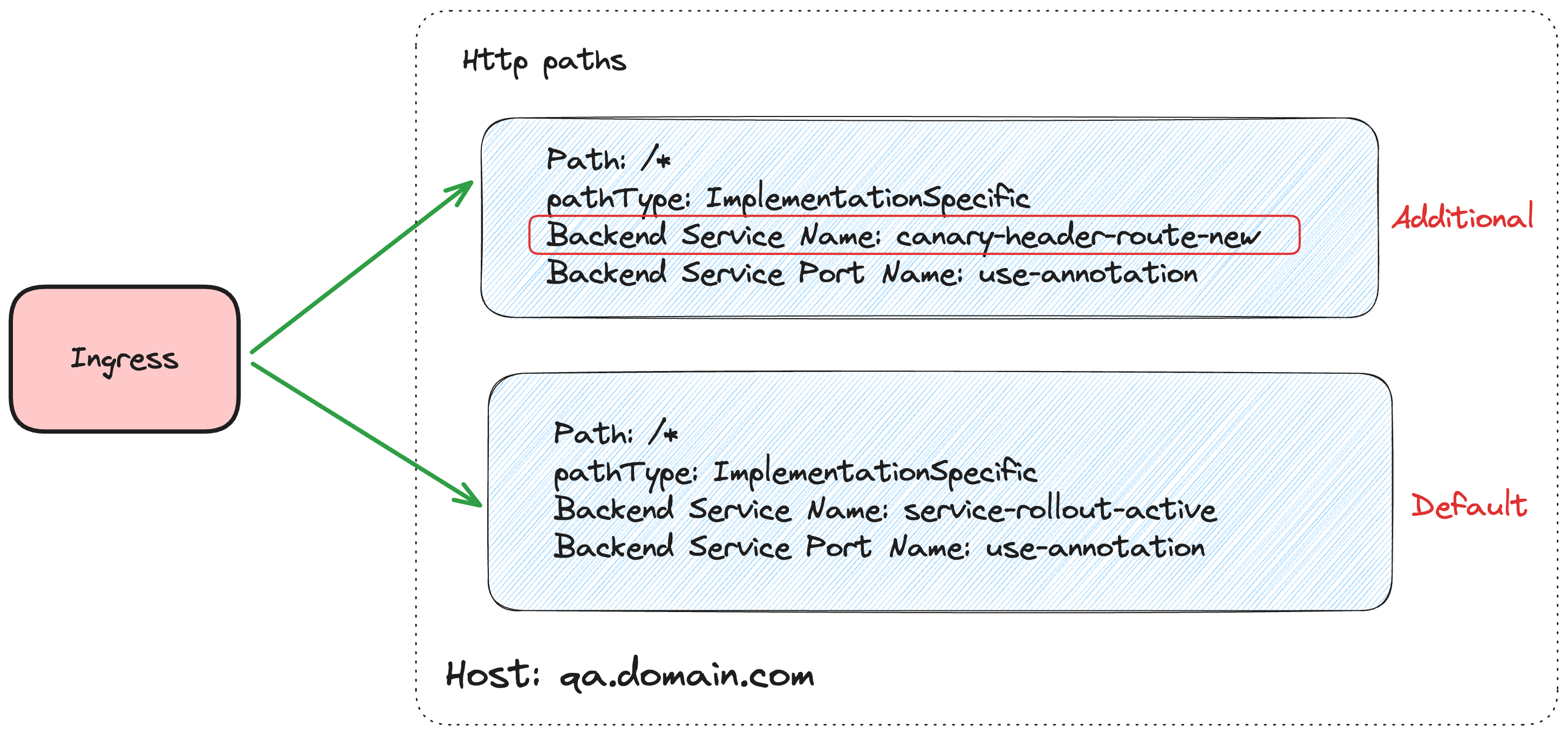
spec:
ingressClassName: alb
rules:
- host: qa-domain.com
http:
paths:
- backend:
service:
name: canary-header-route-new
port:
name: use-annotation
path: /*
pathType: ImplementationSpecific
- backend:
service:
name: service-rollout-active
port:
name: use-annotation
path: /*
pathType: ImplementationSpecific
Consider that we have one path in ingress that will point to our service, Canary/Active, based on which is holding traffic. When we enable header-based routing, it will add one more path with the same configuration; the only difference is the service name, which is equal to the name we gave when defining the canary step. If you remember the below step,
- setHeaderRoute:
match:
- headerName: version
headerValue:
exact: "2"
name: canary-header-route-new
So, you might be wondering where this traffic between the services is specified and which service to point to currently. This is done by the annotation, which is then understood by the alb controller.
Let’s look into the action annotation, which tells us which service is holding the traffic.
alb.ingress.kubernetes.io/actions.service-rollout-active: >-
{"Type":"forward","ForwardConfig":{"TargetGroups":[{"ServiceName":"service-rollout-canary","ServicePort":"80","Weight":0},
{"ServiceName":"service-rollout-root","ServicePort":"80","Weight":100}]}}
Here we can compare that when we give the service name while defining the path in ingress as service-rollout-active. It means that the service name matches the annotation and accordingly sends traffic to particular services with a percentage.
Now, when we enable header-based routing, it will add one more annotation as follows:
alb.ingress.kubernetes.io/actions.canary-header-route-new: >-
{"Type":"forward","ForwardConfig":{"TargetGroups":[{"ServiceName":"service-rollout-canary","ServicePort":"80","Weight":100}]}}
So, as we can see, the active one is Root, which is currently holding 100% of traffic, and in the next iteration, it will be shifted to Canary, which is then pointed by the header route also.
Hence, All this configs are added by rollout on the fly, which then Auto Synced by ArgoCD and remove this configs
Solution
To address this gap and enable the use of header-based routing, we devised a workaround. The solution involved instructing ArgoCD to ignore specific changes made by Argo Rollout to the Ingress resources. By doing so, we could ensure that the desired configuration for header-based routing was maintained, even though these changes were not reflected in the GitHub repository.
We made modifications to the apps.yaml file in our ArgoCD configuration to instruct it to ignore the specific changes related to the Ingress resources. Here’s a snippet of the relevant configuration:
ignoreDifferences:
- group: networking.k8s.io
kind: Ingress
jqPathExpressions:
- >-
.spec.rules[]?.http.paths[]?|select (.backend.
service.name=="canary-header-route-new")
This configuration specifies that ArgoCD should ignore any changes made to Ingress resources where the backend service points to “canary-header-route-new.” By applying this workaround, we were able to maintain the integrity of our header-based routing configuration despite the OutOfSync issue.
Conclusion
By integrating header-based routing with Argo Rollout and ArgoCD, we’ve effectively safeguarded our production environment against potential bugs. This newfound capability has brought immense satisfaction to our organizational teams, particularly in enabling thorough testing of critical features before full rollout. The fear of introducing bugs into production has been significantly reduced, instilling confidence in our deployment process.
Moreover, the enhanced control over deployments has streamlined our workflow, resulting in a higher frequency of deployments compared to before. However, it’s important to acknowledge that the solutions we’ve implemented are temporary workarounds. We anticipate that future versions of Argo Rollout will address these compatibility issues with ArgoCD, providing a more seamless and integrated deployment experience. We look forward to leveraging these improvements to further optimize our deployment processes in the future.


