We bring to you this weekly series of articles, to help understand and demystify the lexicon in the GenAI space. Here is part 1 - Large Language Model.
Large Language Model
A Large Language Model (LLM) is a deep learning model that has been trained on a massive amount of textual data, hence the name ’large’. Among other capabilities, they can understand and generate text. To put it very, very simply - an LLM has been fed enough examples as part of the training to be able to recognize and interpret human languages. This is why talking to ChatGPT feels so natural, like talking to a human. By virtue of the vast training data, it can also take on various personalities and tones, allowing us to use them in a wide array of contexts.
An LLM is specifically trained on language data. Its inherent strength is that it has an enhanced ‘understanding’ of human languages. To be fair, LLMs are incapable of understanding language the way humans do. But… what an LLM knows is this: given a stream of text, which word should follow such that it makes the most sense in this context. It knows this by virtue of the vast patterns and contexts it has seen in the training data.
To summarize, LLMs work by predicting the next token based on the patterns it has seen in its training data. This is what makes up for its conversational abilities.
LLMs are trained on vast amounts of data collected (typically) from the Internet. GPT-3.5, for example, has been trained on 17 gigabytes of data from the following sources.
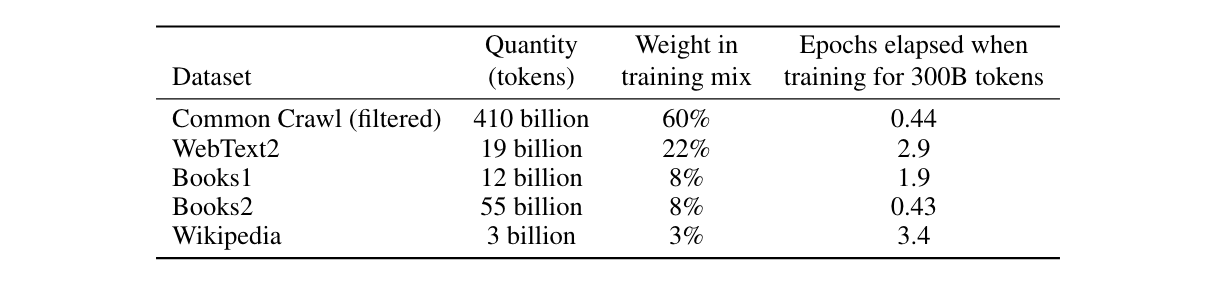
Source - Language Models are Few-Shot Learners
Tokenization
LLMs break down words into tokens when processing and generating text. A ’token’ is the smallest unit of text in the LLM world. A word is made up of one or more tokens. A simple rule of thumb - a token can be considered to be approximately 4 characters in length (this is not true all the time, but on average it works out to be this number). Complex words are composed of multiple tokens; punctuation marks are separate tokens by themselves.
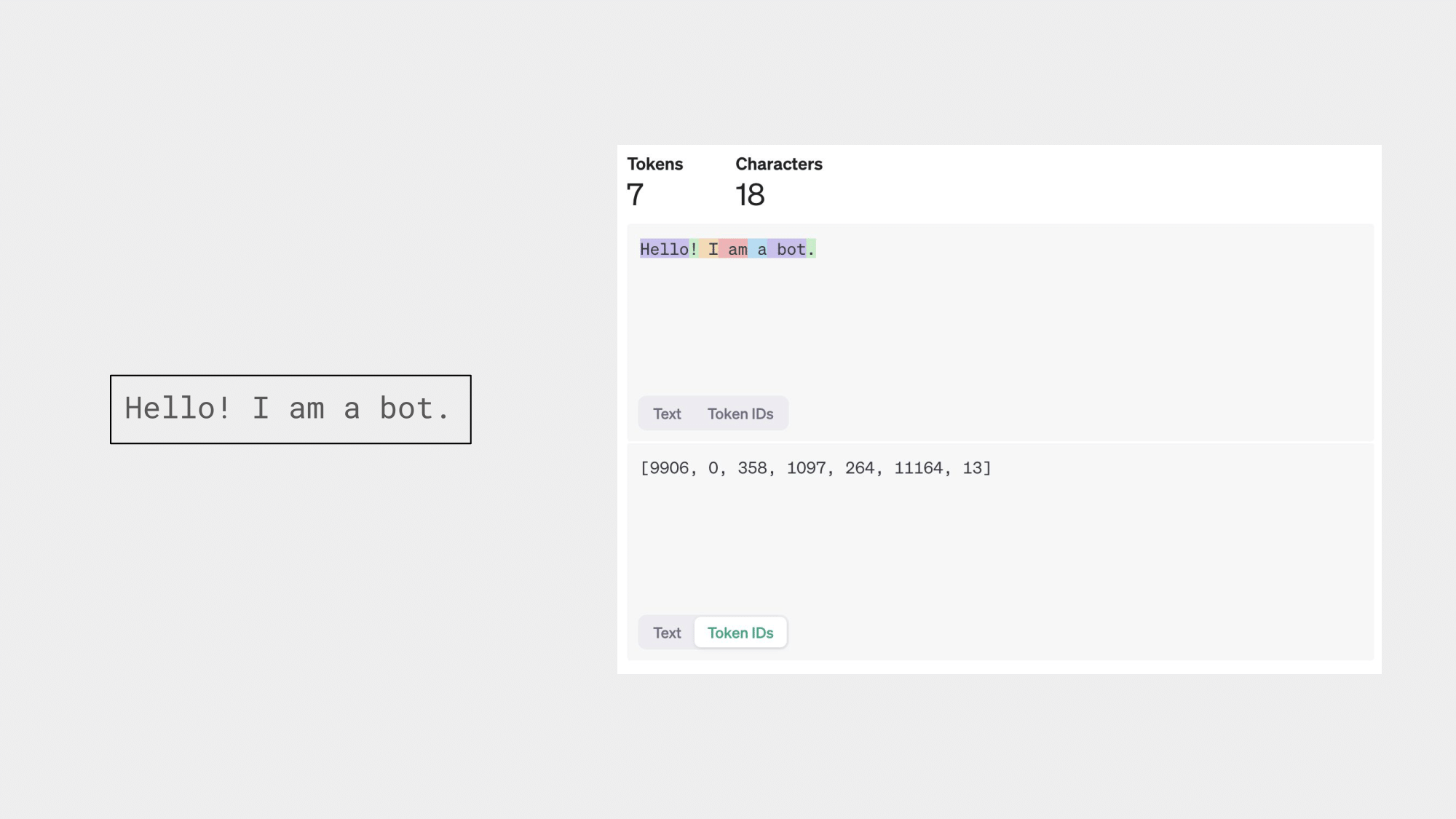
As an example, consider the following sentence.
“Hello! I am a bot.”
Using the OpenAI tokenizer, this text can be broken down into 7 tokens as follows - “Hello”, “!”, " I", " am", " a", " bot", “.”
Now consider a sentence with more complex words.
“Renaissance faires are all the rage these days.”
Using the same OpenAI tokenizer, this can be broken down into tokens as “R”, “ena”, “issance”, " f", “aires”, " are", " all", " the", " rage", " these", " days", “.”

Notice how the words “Renaissance” and “faires” are split into multiple tokens?
But why tokenize? Tokenizing helps to represent the original text in a form that the model can process. Every token is mapped to a unique integer ID based on the model’s vocabulary. This allows the model to use the tokens to process and generate text.
The exact logic of tokenizing varies across the different tokenizers. So it’s important to use the right tokenizer for the chosen LLM. To programmatically count the number of tokens, use the tiktoken OpenAI tokenizer library.
Parameters
Parameters are the weights and biases that the model learns during training. A model with 70 billion parameters (70B model) has a very large capacity to learn complex patterns and representations from the data when compared against a model that has 8 billion parameters (8B model). The larger the parameters, the longer it takes the model to make inferences.
It’s not all rosy…
Despite how versatile LLMs can be, it is not all rosy. There exist some concerning, yet common problems with using LLMs
- Hallucination - Hallucination is when LLMs make up answers that are factually incorrect. It can be difficult to spot when it is hallucinating, especially when the user is not familiar with the subject matter.
- Can carry biases - It is possible for the model to carry biases. This stems from the training data. If the training data had had biases, they could be transferred to the model as well.
- Can be discriminatory - This is also typically a function of the training data. If the training data contained much discriminatory content, the discriminations can pass on to the model-generated text as well.
- It cannot possibly know information it was not trained on. This can cause them to become outdated if used solely in scenarios where the information is updated quickly.
Choosing an LLM
When choosing LLMs, it is important to choose the most suitable LLM for the use case. If you will ultimately be using it in the medical domain, it makes more sense to use an LLM that is built specifically for the medical domain (e.g., Med-PaLM). Similarly, choose models that are trained on and for the language that you’re building for. An LLM trained specifically on Indian languages (e.g., indicLLM) would be better than GPT’s Indian language text generation capabilities.
Tools like LMSys Arena Leaderboard also provide information on how a model ranks against another.
In conclusion…
Large Language Models (LLMs) are deep learning models trained on vast textual data, enabling them to generate human-like text and adapt to various contexts by predicting the next token.
LLMs process text by breaking it into tokens, which are essential for handling text. The number of parameters in an LLM determines its learning capacity and complexity.
LLMs can suffer from hallucination, bias, and outdated information. Selecting the right LLM for a specific domain or language is crucial.


