The blog discusses resolving a deployment issue with 502 errors on AWS EKS using AWS ALB and Argo Rollouts. It details the root cause, attempted solutions, and resulting trade-offs.
Context
We encountered a 502 at the AWS load balancer level during the deployment of one of our client’s service. This resulted in 1-2 minutes of downtime, which was unexpected even if the deployment was carried out during the day (during peak traffic). Nearly 15,000 requests were made to the high-throughput service every minute. Over 10 percent of requests resulted in 502 errors. Even during peak hours, the new version of the service was supposed to be rolled out without interfering with users’ individual requests.
The Deployment Strategy
Presently, all of our client’s services are hosted on AWS EKS using Kubernetes, and all Kubernetes manifests are managed in org, one of which is a GitHub repository that is synchronised with ArgoCD. Since Argo-Rollout Canary offers us the benefit of automated progressive delivery, we have chosen it as our deployment strategy.
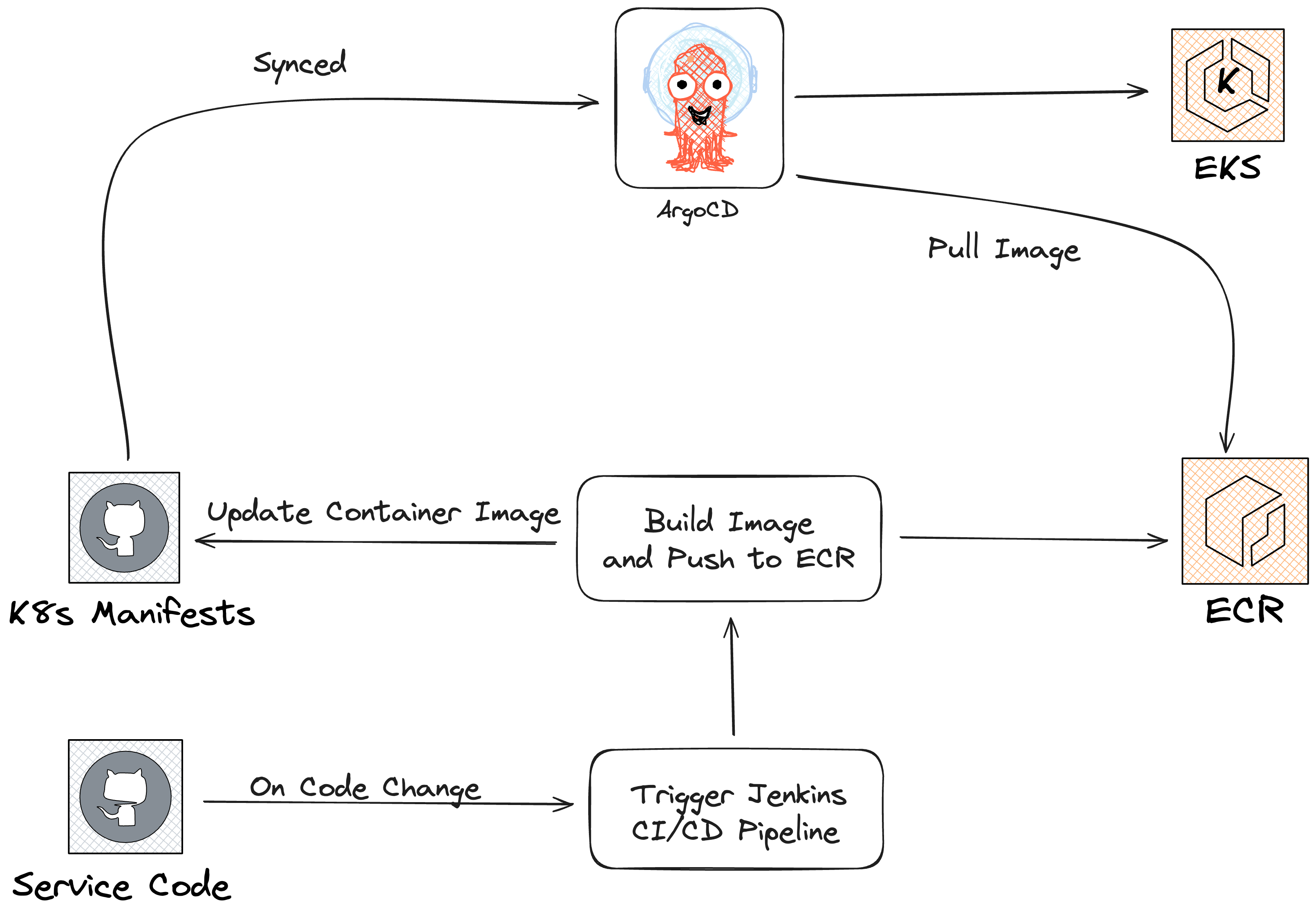
We were using the AWS ALB to route traffic, and it was managing the instructions from the Argo Rollout to move traffic to a new service by using the canary steps specified in the rollout manifests.
Initial Findings
Upon analysing the ALB logs, we discovered that the 502 errors were originating from the older pods.
Theory We were Considering
The way the ALB manages traffic is the main source of the issue. Traffic is directed by the ALB to the specified targets—in this case, pods—when it is received. A termination state is reached by the older pods during a new deployment. Pods should not accept new requests and should, by default, process older ones during the 30-second termination grace period. Nevertheless, the ALB keeps sending requests to pods that are in the termination state during this time, which causes 502 errors to occur.
Solutions We Tried
As far as we know, Kubernetes uses probes to identify unhealthy pods and removes them from the list of service endpoints. Thus, the probes are required. In order for Kubelet to properly communicate with Kubepoxy and remove the endpoint in the event of a failure, we have confirmed the intervals of checks once more.
To give Kube proxy enough time to remove the endpoint from service endpoint lists, we must add an extra delay. Pre-stop hooks were added to allow for a 60-second container-level sleep before pod termination. Following this, the system will send the SIGTERM signal to complete shutdown.
spec: containers: lifecycle: preStop: exec: command: - /bin/sh - '-c' - sleep 60We have included a GraceFullShutdown of 90 seconds so that the application can process the existing requests. Upon receiving a SIGTERM signal, the application will no longer accept new ones and will take some time to process them. We also need to add some code to the application to make it understand that it should gracefully shut down before calling SIGKILL to end the application entirely in order to handle GraceFullShutdown.
spec: terminationGracePeriodSeconds: 90Current configurations are the most important thing that can help us manage requests on older pods from the Kubernetes side, but we also need to consider things from the standpoint of AWS-ALB, since all traffic is routed through AWS-ALB and needs to be routed if the pods are in the termination state.
We increased the interval seconds from 15 to 10 seconds in order to more aggressively check the targets’ health. By doing this, the load balancer won’t send traffic to pods that are in termination state.
metadata: annotations: alb.ingress.kubernetes.io/healthcheck-interval-seconds: "10"Additionally, we want ALB to wait a suitable amount of time before eliminating targets that Kubernetes has labeled as unhealthy or terminated. To account for this, we have included a 30-second deregistration delay.
metadata: annotations: alb.ingress.kubernetes.io/target-group-attributes: deregistration_delay.timeout_seconds=30
Do These Solutions Prove to be Beneficial?
Congratulations! All above configuration was necessary and greatly helped us to reduce the 502s during the deployment but it was not completely removed.
Actual Findings
Interestingly, during our careful observation of the canary deployment steps, we noticed that the problem occurred specifically when we shifted traffic from 90% to 100% in the final canary step.
What Definition Did This Canary Step Have?
canary:
steps:
- setCanaryScale:
weight: 20
- setWeight: 0
- pause: { duration: 60 }
- setCanaryScale:
matchTrafficWeight: true
- setWeight: 10
- pause: { duration: 60 }
- setWeight: 60
- pause: { duration: 60 }
- setWeight: 80
- pause: { duration: 60 }
- setWeight: 90
- pause: { duration: 60 }
- setWeight: 100
- pause: { duration: 60 }
The Argo Rollout canary configurations mentioned above appear to be normal, but the problem only surfaced during the final phase of increasing traffic from 90% to 100%. To be sure, we slightly adjusted the final configuration steps as shown below, which has assisted in bringing down the request count from 10% to 1%.
- setWeight: 90
- pause: { duration: 60 }
- setWeight: 99
- pause: { duration: 60 }
- setWeight: 100
- pause: { duration: 60 }
Root Cause
When we analyse the AWS ALB controller logs, we get to know that an update operation request was received at almost the same time. However, the actual ModifyRule action to change weight was triggered only after about 1 minute and 10 seconds. Ultimately, the problem seems to be that there is a time difference between the lb-controller’s update operation request for weight change and the actual lb-listener rule modification API.
We discovered that our use of dynamicStableScale caused older replica sets to scale down before the traffic shift from the load balancer. This created a lag between the canary weight change and the actual traffic switch from the load balancer, leading to problems. Similar to this, one issue is raised here.
To address this, we disabled dynamicStableScale and increased the scaleDownDelaySeconds from 30 seconds (default) to 60 seconds, which will wait for 60 seconds before scaling down the older replicaset pods.
spec:
strategy:
canary:
dynamicStableScale: false
scaleDownDelaySeconds: 60
This solved the 502 errors entirely, but it came with a trade-off. Although we resolved the issue, we lost the benefit of downsizing the older ReplicaSets during deployment, resulting in doubled CPU, memory, and pod usage temporarily.
Conclusion
Whenever we think of using AWS ALB as traffic routing with Argo Rollout as a deployment strategy, we explicitly need to configure multiple things, which makes it difficult to set up the rollout specs as configurations can vary from application to application. As the limitation of the AWS ALB controller with the Argo Rollout dynamicStableScale while making it true. We lost the advantage of downscaling the pods during the deployment, which then led to doubling the infrastructure, which became the same as the blue and green deployment strategies. As one of the main purposes of using the canary strategy was to not double the infra from a resource and cost perspective, it got lost.


