My Journey with Spark
Before I knew Spark, I mostly used only Pandas and NumPy for data processing. They worked well for small datasets, and I never really had any issues—until I had to process a really large dataset—millions of rows. The processing slowed down, and eventually, I ran into an out of memory error. I tried splitting the data into chunks and tweaking my code, but nothing really worked well.
On top of that, if my process failed due to a network issue, I had to start over. Running these jobs was expensive(long-running EC2 instances), and the time wasted on reruns was frustrating. That’s when I started looking for a better solution.
That’s when I came across Apache Spark. It handles large datasets by distributing the work across multiple machines.
When I ran my first Spark job, I was honestly amazed. It processed my data way faster than Pandas. The coolest part? The driver-executor model. The driver assigns tasks, and the executors do the heavy lifting. If something goes wrong, Spark retries only the failed tasks instead of starting over, offering fault tolerance, and efficient distribution. Plus, it works well with cluster managers like YARN and Kubernetes, making it easy to scale up.
Now, let’s take a closer look at what Spark is and its key components.
Apache Spark is a unified, multi-language (supports Python, Java, Scala, and R) computing engine for executing data engineering, data science, and machine learning on single-node machines or clusters and a set of libraries for parallel data processing.
Let’s break down our description:
Unified: It is designed to handle a wide range of data analytics tasks, from simple SQL queries to machine learning and streaming, all within a single engine using APIs.
Computing Engine: It focuses on computation rather than storage, allowing it to work with various storage systems like Hadoop, Amazon S3, and Apache Cassandra.
Libraries: Spark comes with built-in libraries for diverse use cases, including Spark SQL for database CRUD operations, Structured Streaming for real-time data processing in applications like fraud detection, MLlib for machine learning, and GraphX for graph analytics. It also supports third-party libraries from the open-source community.
Spark Components
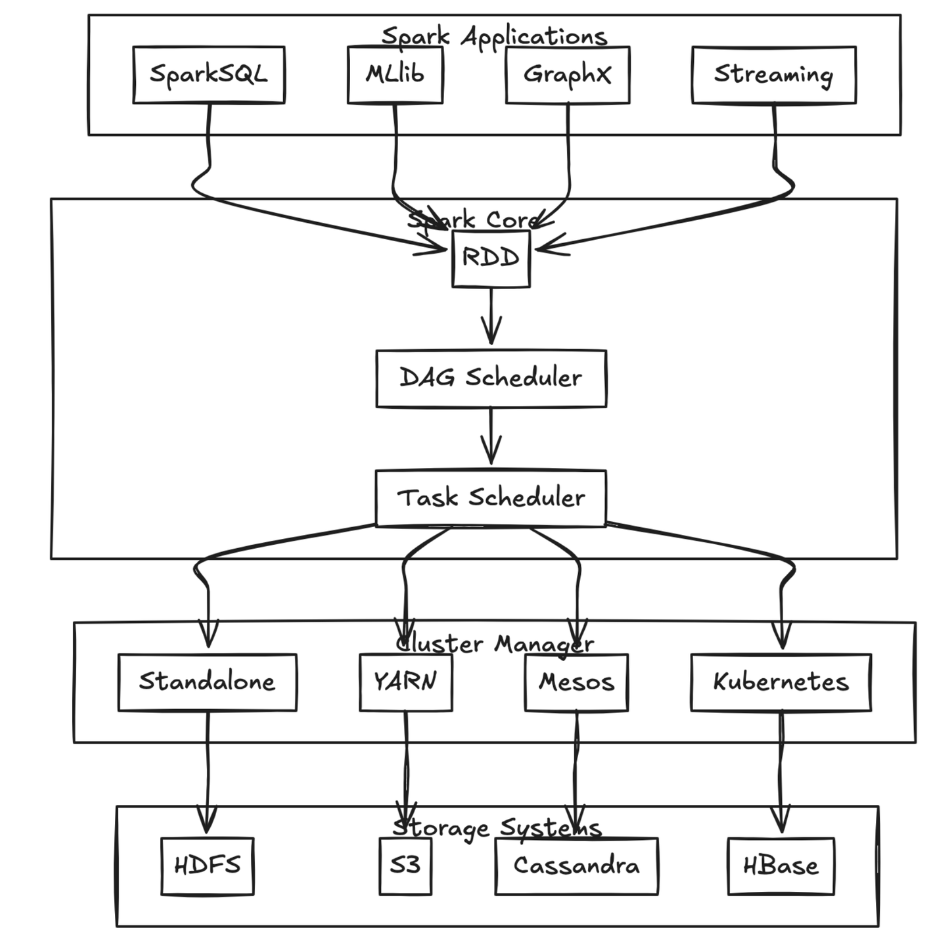
High-Level Components (Spark Applications)
At a high level, Spark provides several libraries that extend its functionality and are used in specialized data processing tasks.
Spark SQL: Spark SQL allows users to run SQL queries on large datasets using Spark’s distributed infrastructure. Whether interacting with structured or semi-structured data, SparkSQL makes querying data easy, using either SQL syntax or the DataFrame API (for now imagine dataframe is just a table of data, like what you see in Excel, more about dataframe is discussed here).
MLlib: It provides distributed algorithms for a variety of machine learning tasks such as classification, regression, clustering, recommendation systems, etc.
GraphX: GraphX is Spark’s API for graph-based computations. Whether you’re working with social networks or recommendation systems, GraphX allows you to process and analyze graph data efficiently using distributed processing.
Spark Streaming: It enables the processing of live data streams from sources like Kafka, or TCP sockets, turning streaming data into real-time analytics.
Spark Core
At the heart of all these specialized libraries is Spark Core. Spark Core is responsible for basic functionalities like task scheduling, memory management, fault tolerance, and interactions with storage systems.
RDDs
RDDs (Resilient Distributed Datasets) are the fundamental building blocks of Spark Core. They represent an immutable, distributed collection of objects that can be processed in parallel across a cluster. More about RDDs is discussed here.
DAG Scheduler and Task Scheduler
DAG Scheduler: Spark breaks down complex workflows into smaller stages by creating a Directed Acyclic Graph (DAG). The DAG Scheduler optimizes this execution plan by determining which operations can be performed in parallel and orchestrating how the tasks should be executed.
Task Scheduler: After the DAG is scheduled, the Task Scheduler assigns tasks to worker nodes in the cluster. It interacts with the Cluster Manager to distribute tasks across the available resources.
Cluster Managers and Storage Systems
Apache Spark can run on multiple cluster managers like, Standalone which is Spark’s built-in resource manager for small to medium-sized clusters, Hadoop YARN (Yet another resource navigator), Apache Mesos, Kubernetes for orchestrating Spark workloads in containerized environments.
For data storage, Spark integrates with a variety of systems like HDFS (Hadoop Distributed File System), Amazon S3, Cassandra, HBase, etc.
Spark’s ability to interact with these diverse storage systems allows users to work with data wherever it resides.
Spark’s Basic Architecture
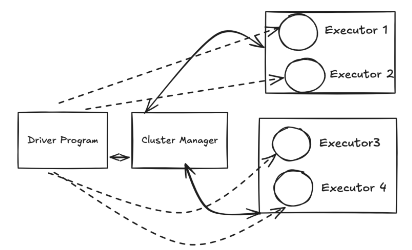
1. Spark Driver
The Spark driver (process) is like the “brain” of your Spark application. It’s responsible for controlling everything. The driver makes decisions about what tasks to run, keeps track of the application’s progress, and talks to the cluster manager to get the computing power needed. Essentially, it manages the entire process and checks on the tasks being handled by worker nodes (executors). So basically it manages the lifecycle of the spark application.
2. Spark Executors
Executors (process) are the “workers” that actually do the processing. They take instructions from the driver, execute the tasks, and send back the results. Every Spark application gets its own set of executors, which run on different machines. They are responsible for completing the tasks, saving data, reporting results, and re-running any tasks that fail.
3. Cluster Manager
The cluster manager is like a “resource manager.” It manages the machines that make up your cluster and ensures that the Spark driver and executors have enough resources (like CPU and memory) to do their jobs. Spark can work with several types of cluster managers, such as YARN, Mesos, or Kubernetes, or it can use its built-in manager.
4. Execution Modes
Spark can run in different ways, depending on how you want to set it up:
Cluster Mode: In this mode, both the driver and executors run on the cluster. This is the most common way to run Spark in production.
Client Mode: The driver runs on your local machine (the client) from where the spark application is submitted, but the executors run on the cluster. This is often used when you’re testing or developing.
Local Mode: Everything runs on a single machine. Spark uses multiple threads for parallel processing to simulate a cluster. This is useful for learning, testing, or development, but not for big production jobs.
Spark’s Low-Level APIs
RDDs (Resilient Distributed Datasets)
They are the fundamental building block of Spark’s older API, introduced in the Spark 1.x series. While RDDs are still available in Spark 2.x and beyond, they are no longer the default API due to the introduction of higher-level abstractions like DataFrames and Datasets. However, every operation in Spark ultimately gets compiled down to RDDs, making it important to understand their basics. The Spark UI also displays job execution details in terms of RDDs, so having a working knowledge of them is essential for debugging and optimization.
An RDD represents a distributed collection of immutable records that can be processed in parallel across a cluster. Unlike DataFrames (High-Level API), where records are structured and organized into rows with known schemas, RDDs are more flexible. They allow developers to store and manipulate data in any format—whether Java, Scala, or Python objects. This flexibility gives you a lot of control but requires more manual effort compared to using higher-level APIs like DataFrames.
Key properties of RDDs
Fault Tolerance: RDDs maintain a lineage graph that tracks the transformations applied to the data. If a partition is lost due to a node failure, Spark can recompute that partition by reapplying the transformations from the original dataset.
In-Memory Computation: RDDs are designed for in-memory computation, which allows Spark to process data much faster than traditional disk-based systems. By keeping data in memory, Spark minimizes disk I/O and reduces latency.
Creating RDDs
Now that we discussed some key RDD properties, let’s begin applying them so that you can better understand how to use them.
from pyspark import SparkContext
# Create a SparkContext
sc = SparkContext("local", "RDD Example")
# Create an RDD directly from a list
numbers = [1, 2, 3, 4, 5]
rdd = sc.parallelize(numbers)
# Now we can perform operations on this RDD
squared = rdd.map(lambda x: x * x)
print(squared.collect()) # [1, 4, 9, 16, 25]
Here think of RDDs like taking a list of numbers and splitting it up so different computers can work on different parts at the same time.
Spark’s Structured APIs
DataFrame
The Spark DataFrame is one of the most widely used APIs in Spark, offering a high-level abstraction for structured data processing.
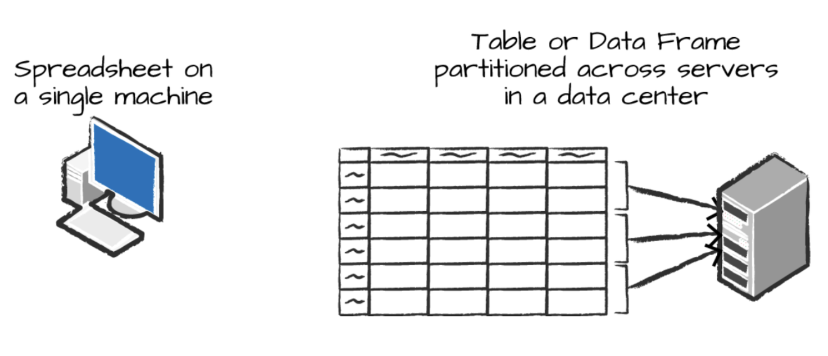
It is a powerful Structured API that represents data in a tabular format, similar to a spreadsheet, with named columns defined by a schema. Unlike a traditional spreadsheet, which exists on a single machine, a Spark DataFrame can be distributed across thousands of computers. This distribution is essential for handling large datasets that cannot fit on one machine or for speeding up computations.
While the DataFrame concept is not unique to Spark; R and Python also include DataFrames—these are typically limited to a single machine’s resources. Fortunately, Spark’s language interfaces allow for easy conversion of Pandas DataFrames in Python and R DataFrames to Spark DataFrames, enabling users to leverage distributed computing for enhanced performance.
Below is a comparison of distributed versus single-machine analysis.
Creating a Dataframe
from pyspark.sql import SparkSession
# Initialize Spark session
spark = SparkSession.builder.appName("DF_from_List").getOrCreate()
data = [1, 2, 3, 4, 5]
# Convert list to DataFrame
df = spark.createDataFrame([(x,) for x in data], ["Numbers"])
# Show DataFrame
df.show()
When you have huge amounts of data, Spark splits it into smaller chunks (which we’ll learn about as “partitions”) so different computers can process different parts at the same time.
Partitions
Spark breaks up data into chunks called partitions, allowing executors (workers) to work in parallel. A partition is a collection of rows that reside on a single machine in the cluster. By default, partitions are sized at 128 MB, though this can be adjusted. The number of partitions affects parallelism—fewer partitions can limit performance, even with many executors, and vice versa.
Transformations
In Spark DataFrames, partitions are usually not managed directly. Instead, high-level transformations are defined, and Spark handles the execution details. Lower-level APIs like RDDs are available for more granular control.
In Spark, the core data structures are immutable, meaning once they’re created, they cannot be changed. This may seem odd at first, but you modify a DataFrame by instructing Spark on how you want to transform it. These instructions are called transformations.
For example, to filter out even numbers from a dataframe, you would use:
divBy2 = myRange.where("number % 2 = 0") # myRange is a dataframe
This code performs a transformation but produces no immediate output. That’s because they are lazy, meaning they do not execute immediately; instead, Spark builds a Directed Acyclic Graph (DAG) of transformations that will be executed only when an action is triggered. Transformations are the heart of Spark’s business logic and can be of two types: narrow and wide.
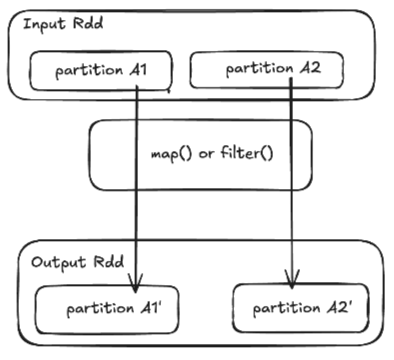
Narrow Transformations
In a narrow transformation, each partition of the parent RDD/DataFrame contributes to only one partition of the child RDD/DataFrame. Data does not move across partitions, so the operation is local to the same worker node. These are efficient because they avoid shuffling (data transfer between nodes).
Examples: map, filter
Wide Transformations
In a wide transformation, data from multiple parent RDD/DataFrame partitions must be shuffled (redistributed) to form new partitions. These operations involve network communication, making them more expensive.
Examples: groupByKey, reduceByKey, join
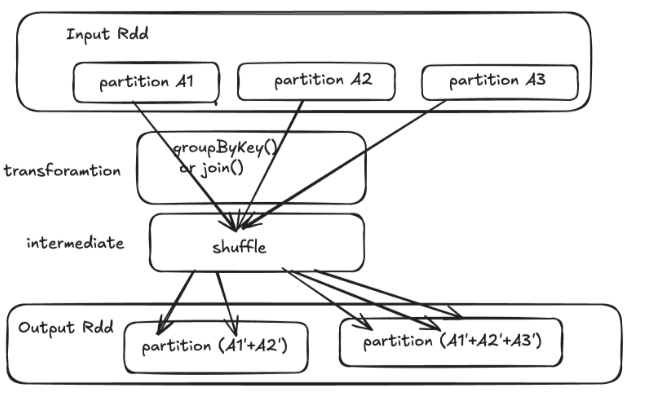
In Spark, transformations are lazy, meaning they don’t execute immediately. Instead, they build a logical plan that outlines how data should be processed. However, to actually compute and retrieve results, we need actions.
Actions
They are operations that trigger the execution of transformations and return results to the driver program. Actions are the point where Spark evaluates the lazy transformations applied to an RDD, DataFrame, or Dataset.
Examples: collect, count
When an action is invoked, Spark builds a DAG (Directed Acyclic Graph) of all preceding transformations and executes the optimized plan.
Key Differences Between Transformations and Actions
| Transformations | Actions | |
|---|---|---|
| Execution | Lazy (no immediate execution) | Eager (triggers computation) |
| Output | New RDD/DataFrame | Result or persisted output |
| Examples | map, filter, groupBy | collect, count, take |
| Purpose | Defines the computation logic | Finalizes and executes the logic |
Now that we’ve covered some key Spark concepts, Let’s explore the different ways to install and execute Spark.
Run Spark Locally
Install Java (required as Spark is written in Scala and runs on the JVM) and Python (if using the Python API).
Visit Spark’s download page, choose “Pre-built for Hadoop 2.7 and later,” and download the TAR file.
Extract the TAR file and navigate to the directory.
Launch consoles in the preferred language:
Python:
./bin/pysparkScala:
./bin/spark-shellSQL:
./bin/spark-sql
Run Spark in the Cloud
No installation required; provides a web-based interactive notebook environment.
Option: Use Databricks Community Edition [free]
Building Spark from Source
Source: Download the source code from the Apache Spark download page.
Instructions: Follow the README file in the source package for building Spark.
Conclusion
Apache Spark has revolutionized the way we handle large-scale data processing, providing speed, fault tolerance, and scalability. From my initial struggles with Pandas and NumPy to embracing Spark’s powerful distributed computing capabilities, the journey has been eye-opening. Whether you’re dealing with batch processing, real-time streaming, or machine learning workloads, Spark offers the flexibility and efficiency required to tackle complex data challenges.
Thanks for reading this blog! We’ve covered an overview of Spark’s components and architecture. In the next blog, we’ll explore its functionality in depth and understand how it handles large-scale data processing efficiently. Stay tuned!


